大模型技术在推荐算法上的探索与应用
前言:相关概念释义
Scaling Law(缩放定律)
核心观点:模型性能(如损失函数值)与计算量、数据量、模型参数量呈幂律关系(Power Law);指导大模型训练的资源分配,明确“规模扩展”对性能提升的边际效益。
演进路线:2010年:OpenAI首次系统性提出Scaling Law(2020年GPT-3验证)。2022年:Chinchilla定律指出数据与计算需平衡扩展(如70B模型需1.4T tokens)。2023年:多模态/稀疏化模型验证定律泛化性。
业界应用:指导模型参数量与训练数据配比(如大模型选型);通过小模型蒸馏、MoE架构突破算力限制。
ICL(In-Context Learning,上下文学习)
核心观点:通过输入上下文示例(Few-shot Prompt)引导模型推理,无需微调;Attention机制隐式对齐示例与任务模式,激活预训练知识;零样本/少样本场景快速适配,降低部署成本。
演进路线:2020年:GPT-3首次展示ICL潜力。2022年:MetaICL提出任务无关的示例选择策略。2023年:RETA-LLM等框架优化示例排序与推理路径。
业界应用:冷启动用户兴趣挖掘
CoT(Chain-of-Thought,思维链)
核心观点:核心思想:通过分步推理(Step-by-Step Reasoning)模拟人类逻辑链条;通过Prompt设计(“Let’s think step by step”)或模型自生成中间步骤实现。;提升复杂任务(如多目标排序)的可解释性与准确性。
演进路线:思维链的概念最早由谷歌在2022年提出,此后被广泛应用于各类大模型中。2022年:Google提出CoT框架,在数学推理任务中验证有效性。2023年:Auto-CoT实现自动化思维链生成,降低人工设计成本。扩展方向:Tree of Thoughts(ToT)支持多路径推理。
业界应用:生成可解释的推荐理由;优化跨品类推荐的长链条决策逻辑等。
一、什么是思维链
1.1 CoT开山之作:Language Models are Few-Shot Learners
Jason Wei 等人提出了思维链提示的方法,大幅提升大模型的逻辑推理能力。具体来说,有三个不一样:
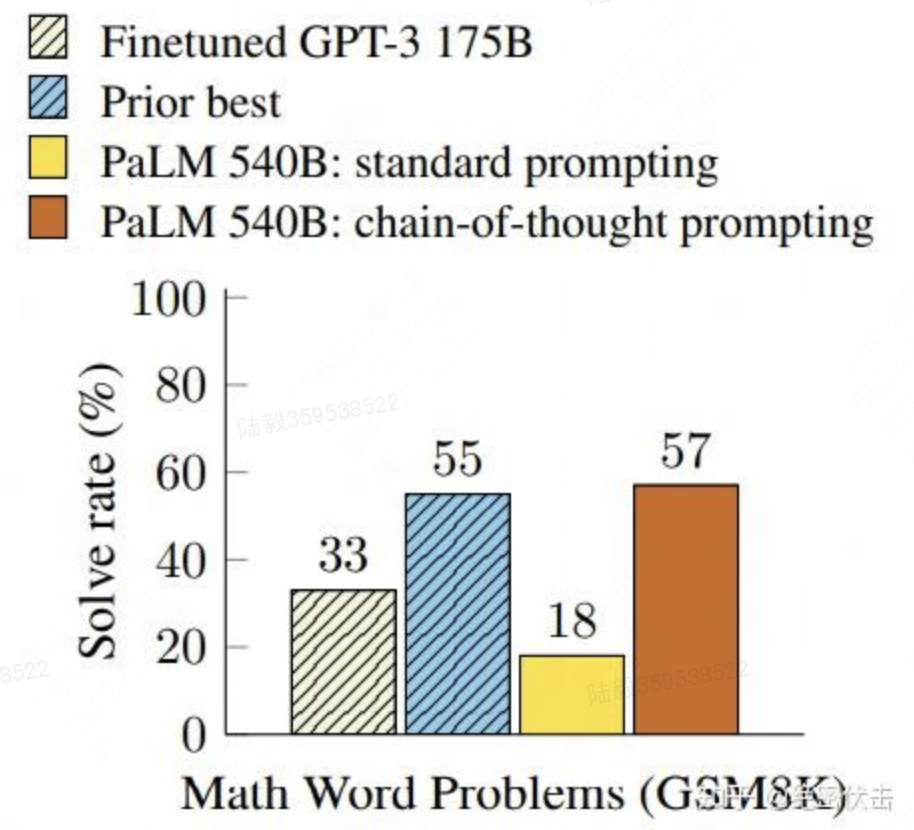
常识推理能力赶超人类。以前的语言模型,在很多挑战性任务上都达不到人类水平,而采用思维链提示的大语言模型,在 Bench Hard(BBH) 评测基准的 23 个任务中,有 17 个任务的表现都优于人类基线。比如常识推理中会包括对身体和互动的理解,例如在运动理解方面,思维链的表现就超过了运动爱好者(95% vs 84%)。
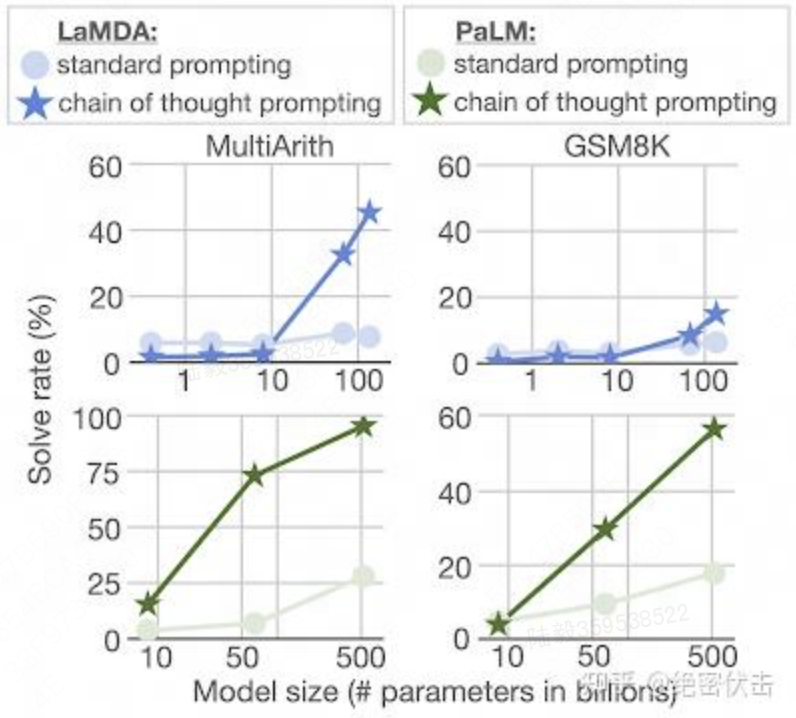
数学逻辑推理大幅提升。一般来说,语言模型在算术推理任务上的表现不太好,而应用了思维链之后,大语言模型的逻辑推理能力突飞猛进。采用思维里技术的大语言模型PaLM比传统提示学习的性能提高了 300%。在 MultiArith 和 GSM8K 上的表现提升巨大,甚至超过了有监督学习的最优表现。这意味着大语言模型也可以解决那些需要精确的、分步骤计算的复杂数学问题了。
大语言模型更具可解释性,更加可信。我们知道超大规模的无监督深度学习,打造出来的大模型是一个黑盒,推理决策链不可知,这就会让模型结果变得不够可信。而思维链将一个逻辑推理问题,分解成了多个步骤,来一步步进行,这样生成的结果就有着更加清晰的逻辑链路,提供了一定的可解释性,让人知道答案是怎么来的。
1.2 CoT技术细节
CoT 的本质是一种提示方法,它鼓励大语言模型解释其推理过程。其主要思想是通过向大语言模型展示一些少量的 exapmles,在exapmles中解释推理过程,大语言模型在回答提示时也会显示推理过程。这种推理的解释往往会引导出更准确的结果。
以一个数学题为例:

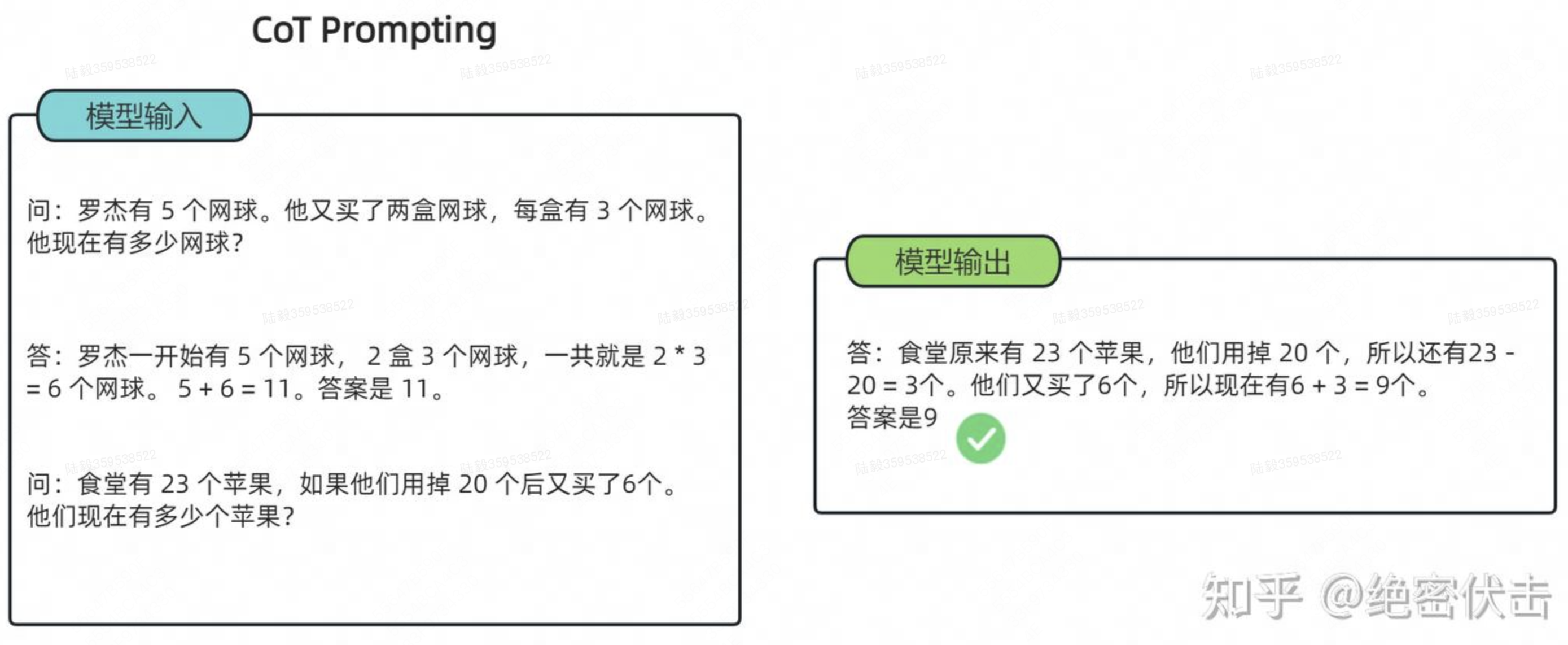
可以看到模型无法做出正确的回答。但如果说,我们给模型一些关于解题的思路,就像我们数学考试,都会把解题过程写出来再最终得出答案,不然无法得分。
可以看出,CoT 在实现上修改了每个 example 的 target:从原先的 answer(a) 换成了 rational(r) + a。因此,COT让模型不是单独生成 a,而是生成r+a。因此 CoT 的优势在于把一个多步推理问题分解出多个中间步骤,并且让 LLM 更加可解释。
简单来说,语言模型很难将所有的语义直接转化为一个方程,因为这是一个更加复杂的思考过程,但可以通过中间步骤,来更好地推理问题的每个部分。因此,思维链提示,就是把一个多步骤推理问题,分解成很多个中间步骤,分配给更多的计算量,生成更多的 token,再把这些答案拼接在一起进行求解。
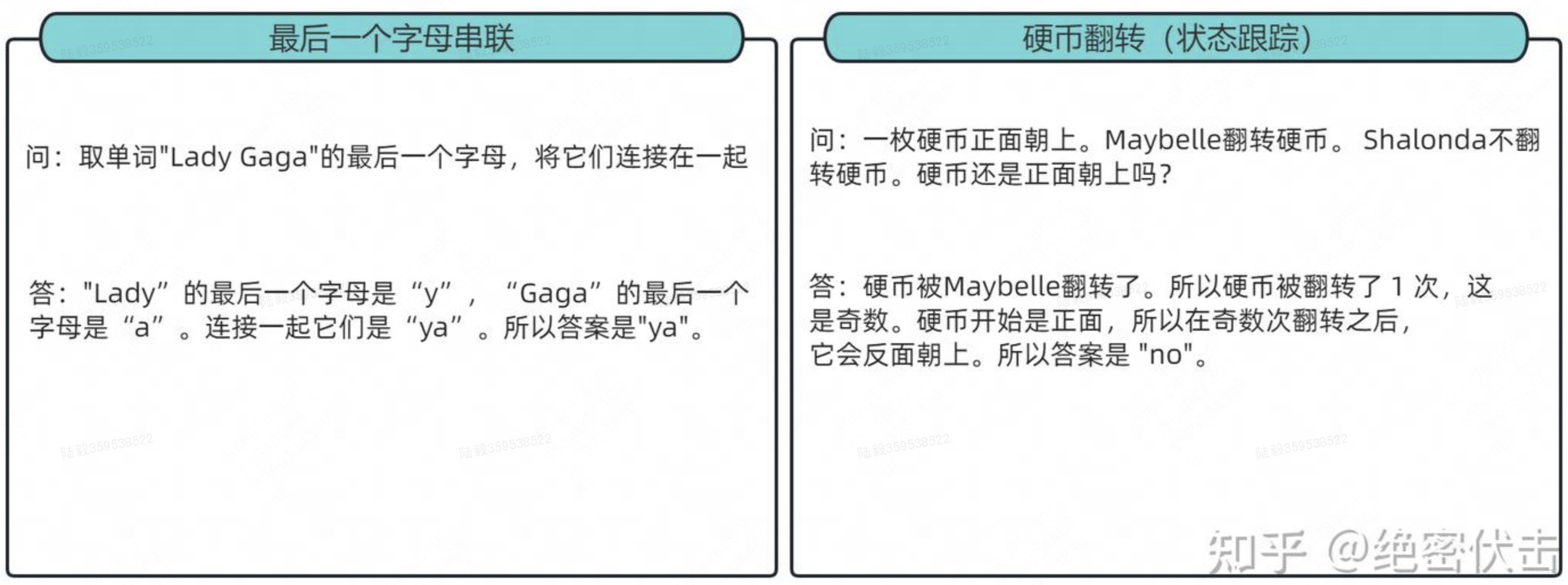
除了上述的数学应用题,还有常识推理、以及 symbolic manipulation (符号操作)这类任务(就是一些手造的考验大模型的问题,比如最典型的 Last Letter Concatenation(最后一个字母串联) 和 coin flip(抛硬币)),下面补充几个例子方便理解:
1.3 神奇的Prompt:Zero-shot-CoT
零样本思维链(Zero Shot Chain-of-Thought,Zero-shot-CoT)是对 CoT prompting 的后续研究,其引入了一种非常简单的零样本提示。他们发现,通过在问题的结尾附加“Let's think step by step”这几个词,大语言模型能够生成一个回答问题的思维链。从这个思维链中,他们能够提取更准确的答案。
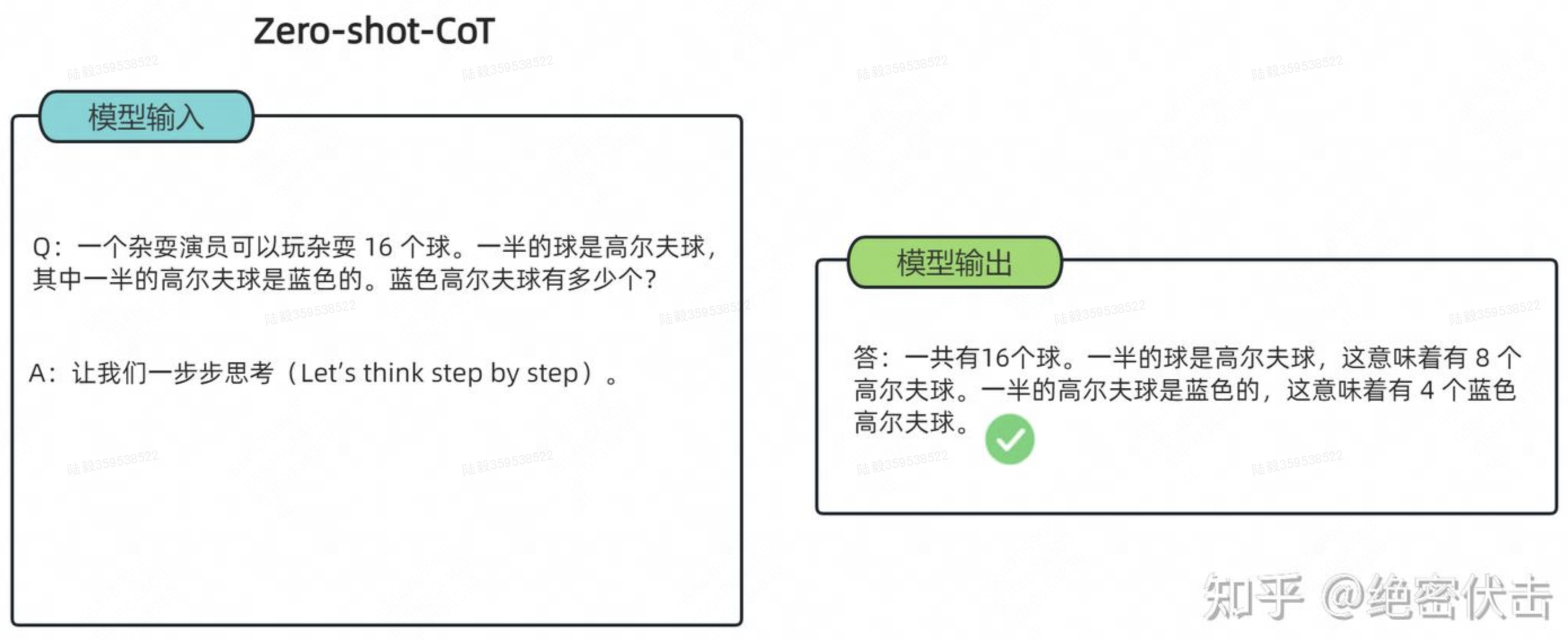
其实 Zero-shot-CoT 是一个 pipeline。也就是说“Let's think step by step”这句话,只是通过这个 prompt 让LLM尽可能生成一些思考过程,然后再将生成的 rationale(理由) 和 question 拼在一起,重新配合一个answer 指向的 prompt 如“The answer is ”来激励模型生成答案。
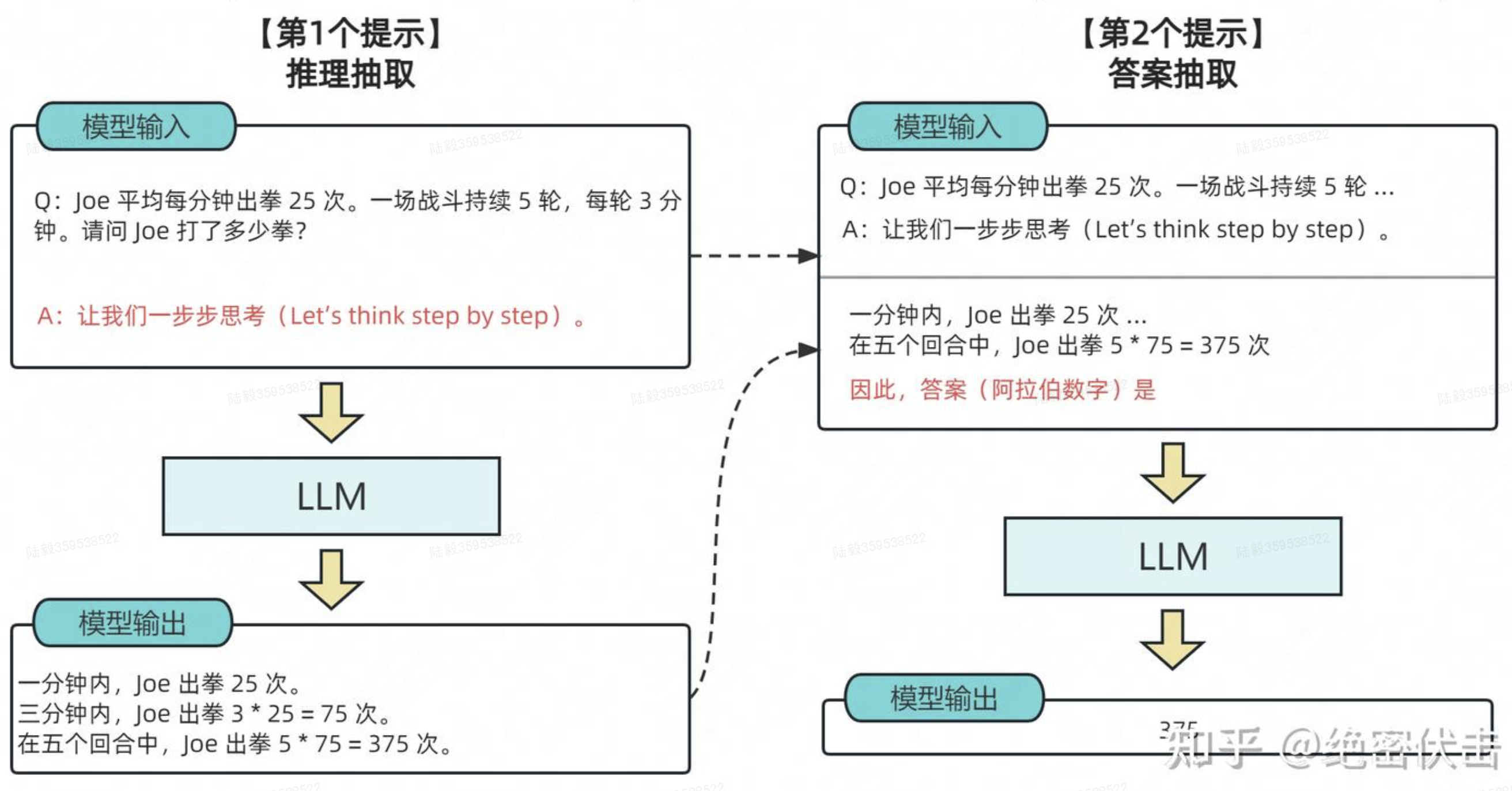
从技术上讲,完整的零样本思维链(Zero-shot-CoT)过程涉及两个单独的提示/补全结果。在下图中,左侧生成一个思维链,而右侧接收来自第一个提示(包括第一个提示本身)的输出,并从思维链中提取答案。这个第二个提示是一个自我增强的提示。
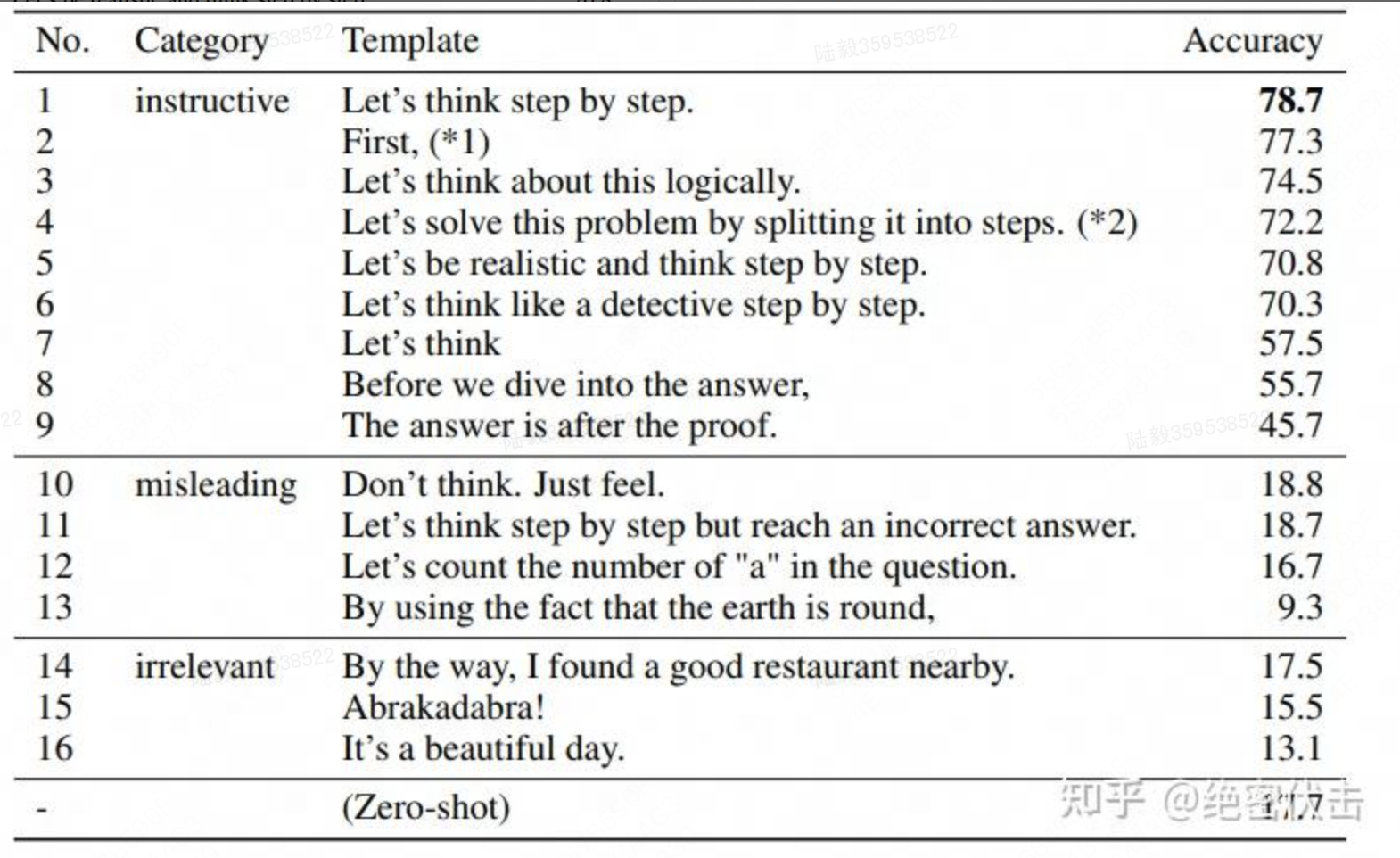
作者还做了解释,说明这句“Let's think step by step”是经过验证的,比如对比下面的其它的 instruction,尤其那些不相关的和误导的,效果就非常差,说明大模型真的是在理解这句 instruction 的意思。
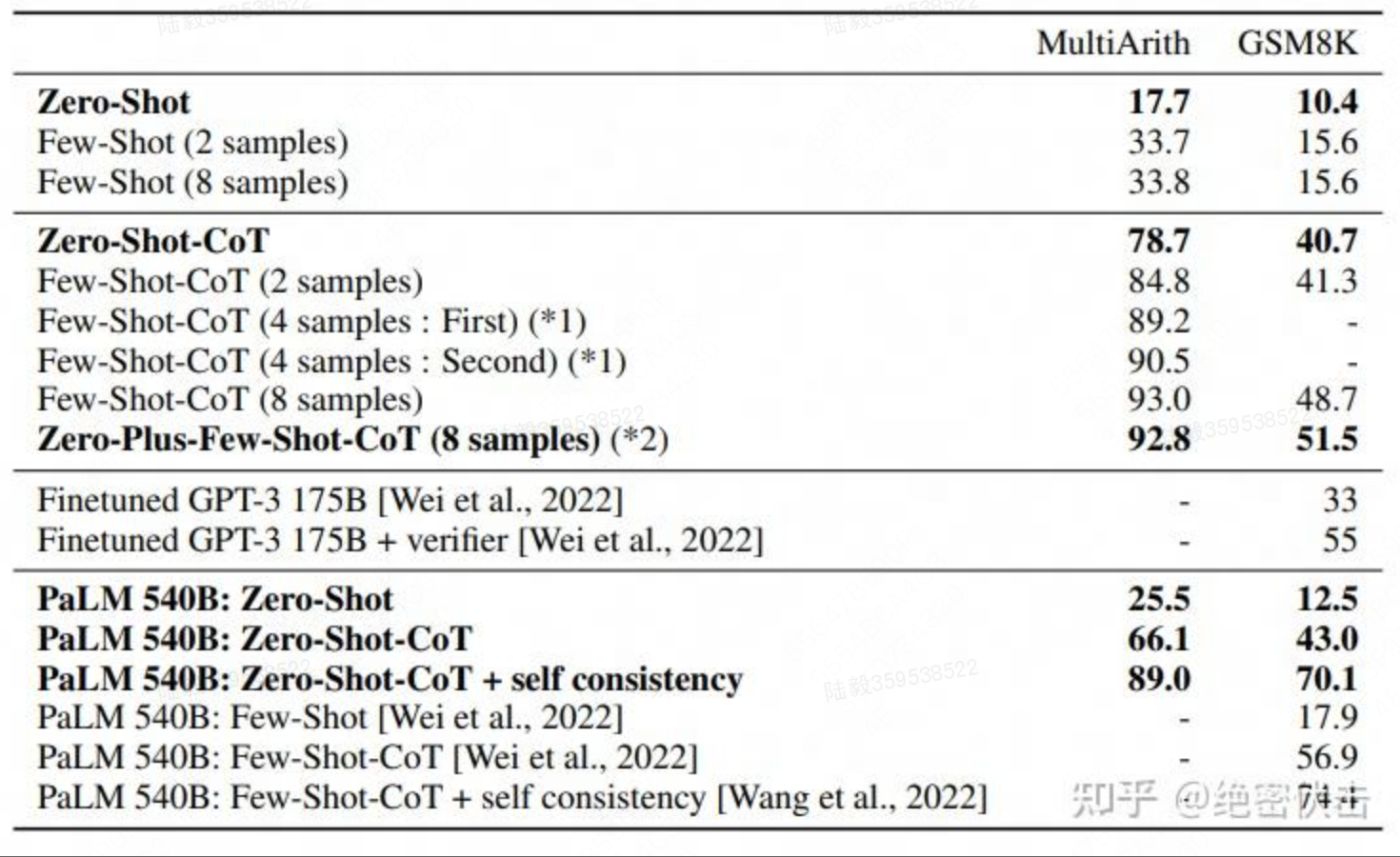
在 GPT-3 上的实验效果:
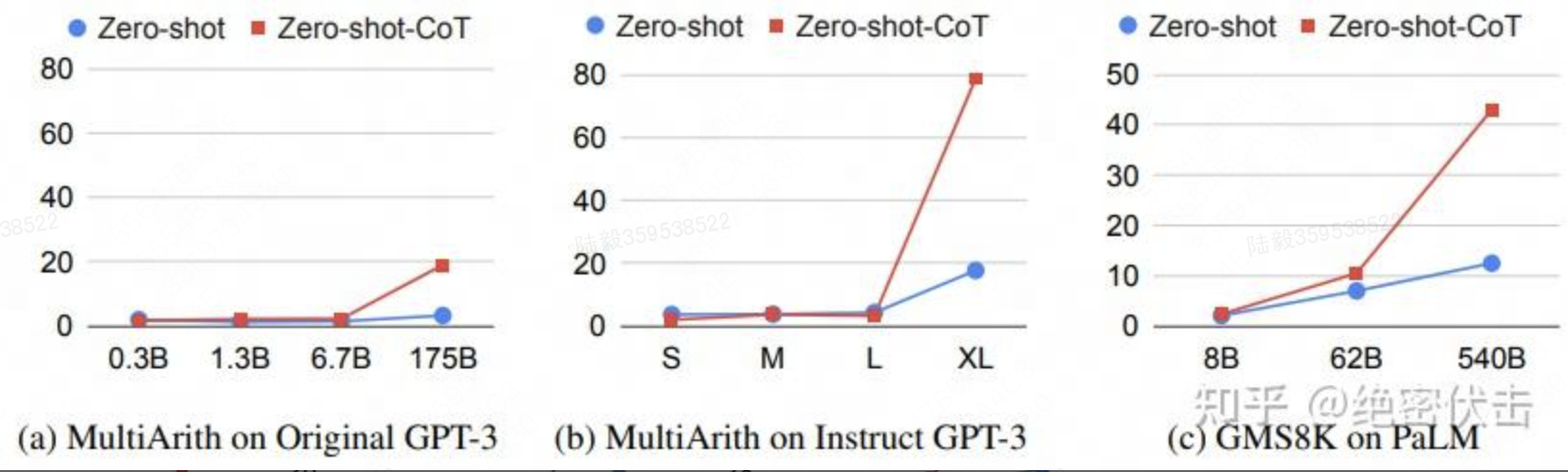
Zero-Shot-CoT 能让 GPT-3 从 17 提升到 78,换到 PaLM 上提升幅度稍微小点,25 到 66。
1.4 提升小模型的推理能力:Fine-tune-CoT
然而,基于 CoT 方法的主要缺点是它需要依赖于拥有数百亿参数的巨大语言模型。由于计算要求和推理成本过于庞大,这些模型难以大规模部署。因此,来自韩国科学技术院的研究者努力使小型模型能够进行复杂的推理,以用于实际应用。
有鉴于此,论文提出了一种名为 Fine-tune-CoT 的方法,该方法旨在利用非常大的语言模型的思维链推理能力来指导小模型解决复杂任务。
为了详细说明,下面应用前面的 Zero-shot-CoT从非常大的教师模型中生成推理,并使用它们来微调较小的学生模型。
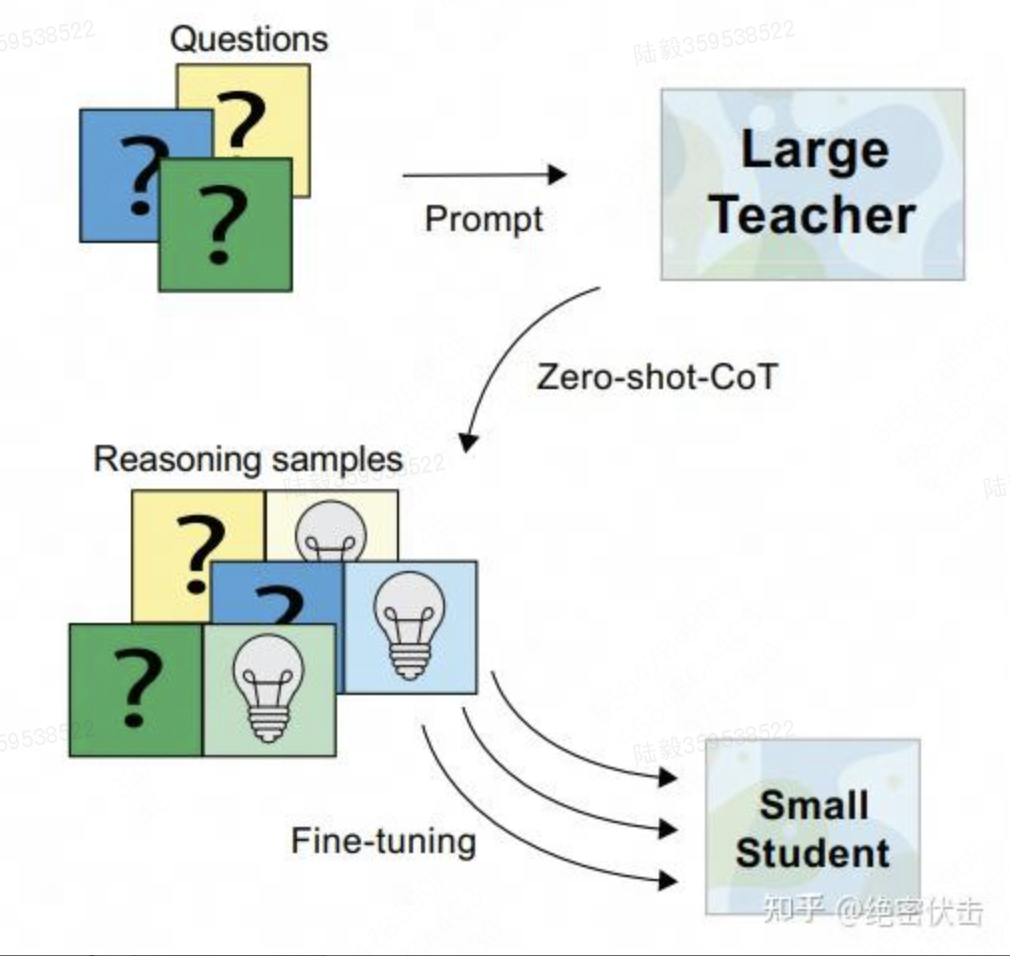
与标准的 prompting 类似,对于训练语言模型来解决复杂推理的任务来说,纯微调往往是不够的。虽然已经有人尝试用规定好的推理步骤对小模型进行微调来解决这个问题,但这些方法需要巨量的推理注释,而且往往还需要与特定任务匹配的训练设置。
论文中提出的方法,由于基于语言模型的教师具有显著的零样本推理能力,无需手工制作推理注释及特定任务设置,可以很容易地应用于新的下游任务。从本质上讲,论文的方法保留了基于 CoT 的多功能性,同时模型规模还不是很大。
Fine-tune-CoT 的核心思想是采用 Zero-Shot-CoT 生成我们的问答数据,然后使用温度 T 采样(也可以用 Top-k 采样),以此生成尽可能多的数据,然后再进行 Fine-tune。其实就是使用不同的温度参数 T 采样,用 ChatGPT 这样的大模型生成 CoT 数据,然后再用小模型进行 Fine-tune。
1.5 CoT衍生范式
单纯的思维链应用场景非常局限,为了打破这样的局限,对思维链的推理结构做出了改进,以适应不同的应用场景,如下图,我们介绍一下思维链的不同推理结构:
PoT(programme-of-thought):针对思维链中可能出错的计算问题,让大模型生成编程语言在解释器中运行,以将复杂计算和文本生成两个任务解耦
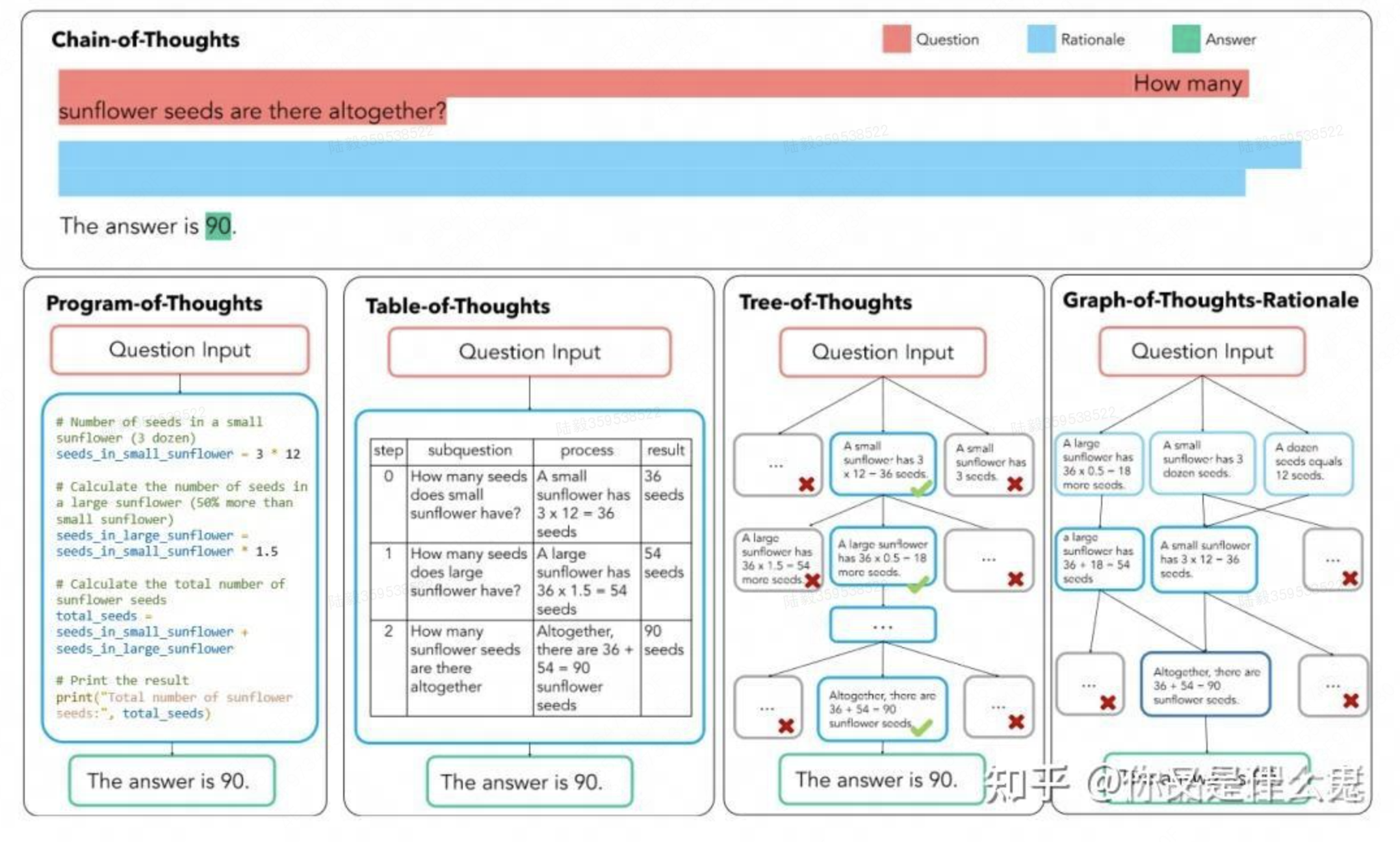
实际上,大模型思维链由于它对大模型性能和大模型可解释性的提升幅度很大,现在也扩展到多模态大模型和大模型智能体中进行使用,均取得很好的效果。总的来说,大模型思维链解决了大模型面对复杂问题时无法得到带有推导过程的输出结果的问题,不仅为各个行业提供有效使用大模型的方法,还为大模型复杂推理得到有效输出开创了先河。在AI应用开发方面,可以通过CoT的精细化提示从现有多参数大模型中爬取噪声比较小的专有化输入输出对数据,还能使用其思维方式部署有效的大模型智能体,同时对需要进行数理逻辑推导和代码编写的大模型,提供了输入数据构造的提示范式。
1.6 CoT的局限性与未来方向
1.6.1 局限性
速度和资源消耗:思维链虽然提高了推理能力,但由于需要生成详细的推理步骤,导致模型的响应速度较慢,并且需要更多的计算资源。这在处理大规模请求或实时应用时可能成为瓶颈。
依赖人工设计:尽管自动思维链技术(Auto-CoT)可以自动生成推理链,但在某些情况下,仍然需要人工设计或调整思维链提示词。对于复杂的任务,设计有效的思维链提示词可能具有挑战性,并且需要专业知识。
缺乏严谨性:思维链生成的推理步骤可能不够严谨,尤其是在处理复杂的数学或逻辑问题时。与人类专家的严谨推理相比,模型的推理过程可能存在跳跃或不完整的情况。未来的研究需要探索如何提高思维链的严谨性。
1.6.2 未来方向
提高思维链的严谨性:未来的研究可以探索如何使思维链的推理过程更加严谨,特别是在处理复杂的数学和逻辑问题时。这可能需要引入更多的形式语言和符号逻辑,提高模型的推理准确性。
优化自动思维链技术:进一步研究自动思维链(Auto-CoT)技术,提高其自动化程度和效率。通过改进聚类算法和提示词生成策略,使自动思维链能够更智能地处理各种类型的问题。
探索新的学习范式:研究人员可以探索结合思维链与其他学习范式,如强化学习、模仿学习等,以进一步提高模型的推理能力和泛化能力。通过多种学习方法的协同作用,使模型能够更好地应对各种复杂任务。
多模态思维链:将思维链扩展到多模态数据,如图像、音频等,是未来的一个重要研究方向。通过构建多模态思维链,模型能够处理更广泛的输入信息,提高在多模态任务中的推理能力。
二、CoT探索
大模型的CoT(Chain of Thought)能力可以通过以下几个方面应用在推荐算法中:
理解用户意图:CoT能力可以帮助大模型更好地理解用户的复杂意图和需求。通过分析用户的历史行为、当前上下文和输入信息,大模型可以推理出用户的潜在兴趣和需求,从而提高推荐的准确性。
用户行为分析:通过分析用户的历史行为(如浏览记录、搜索关键词、购买历史、全链路足迹特征等),大模型可以利用CoT能力推理出用户当前的需求和偏好。
上下文理解:结合用户的地理位置、时间和天气等上下文信息,大模型可以更准确地推断用户的意图。例如,在下雨天,用户可能更倾向于选择室内活动(例如KTV、剧本杀、足疗等),而不是室外活动(野营、户外射箭、真人CS等)。
增强特征工程:在推荐系统中,特征工程是提升模型性能的重要环节。CoT能力可以用于自动化地生成和选择特征。大模型可以通过推理,生成一些复杂的交互特征或上下文特征,帮助模型更好地捕捉用户行为模式。
生成复杂特征:CoT能力可以帮助生成更复杂的特征,例如用户与商户的交互频率(用户-商户交叉特征)、用户的对不同品类的消费意愿等(用户画像特征),从而增强模型的表达能力。
特征选择:通过推理分析,大模型可以自动选择对推荐效果最有影响的特征,减少冗余特征,提高模型效率。
提升个性化推荐:CoT能力能够帮助模型在个性化推荐中更好地理解用户的偏好和需求。例如,大模型推荐系统可以通过CoT分析用户的购买历史、浏览习惯和评价信息,推理出用户可能感兴趣的商品,从而进行个性化推荐。
个性化商户推荐:根据用户的历史偏好和当前意图,大模型可以通过CoT能力推荐个性化的商户。例如,针对一个喜欢尝试新类目供给的“新客”,推荐系统可以优先推荐新开张或评分较高的餐厅。
动态调整推荐:大模型可以实时分析用户的反馈(如点击、收藏、下单等),通过CoT推理动态调整推荐策略,提高推荐的相关性和用户满意度。
解释性推荐:CoT能力还可以用于提升推荐系统的可解释性。大模型可以通过CoT分析,为算法同学提供推荐理由和解释,更容易理解为什么推荐某个项目。这能够帮助后续推荐算法迭代更好地做出决策。
推荐理由:通过CoT分析,大模型可以为每个推荐提供理由,如“因为您最近浏览了多家日式餐厅,我们推荐了这家评分较高的日式料理店”。
增强用户信任:解释性推荐可以增加用户对推荐系统的信任,使用户更容易接受和使用推荐结果。
复杂场景的推荐:在一些复杂场景中,如多目标推荐或情境感知推荐,CoT能力可以帮助大模型进行多步推理,权衡不同目标或情境因素,从而提供更符合用户需求的推荐结果。
多目标优化:在需要综合考虑多个目标(如用户满意度、商户曝光率等)的场景中,CoT能力可以帮助大模型进行多步推理,权衡不同目标,提供最优的推荐结果。
情境感知推荐:在特殊情境(如节假日、促销活动等)下,大模型可以通过CoT推理调整推荐策略,以适应不同的场景需求。
三、LLM业界应用
3.1 LLM应用于精排模型:LLM-CTR结构模型
当前基于强ID特征的推荐系统在个性化推荐方面表现出色,但在泛化能力和对世界知识的利用上仍存在局限。特别是对于中低活跃度用户,这类系统往往无法充分学习其购物偏好,导致发现性推荐的效果不尽如人意。因此,有算法团队提出了一种创新的推荐排序系统架构——LLM-CTR。该架构通过引入LLM的世界知识,并结合原有的ID特征后验优势,共同构建用户与商品之间的关联,从而弥补了ID特征在非活跃用户上的不足,显著提升了推荐结果的多样性和准确性。
LLM-CTR基础模型的完整结构如下图所示,由LLM编码模块和任务预测层两部分组成,其中LLM编码模块部分参与推荐任务端到端的训练,但只有任务预测层会被单独分离出来提供线上服务。
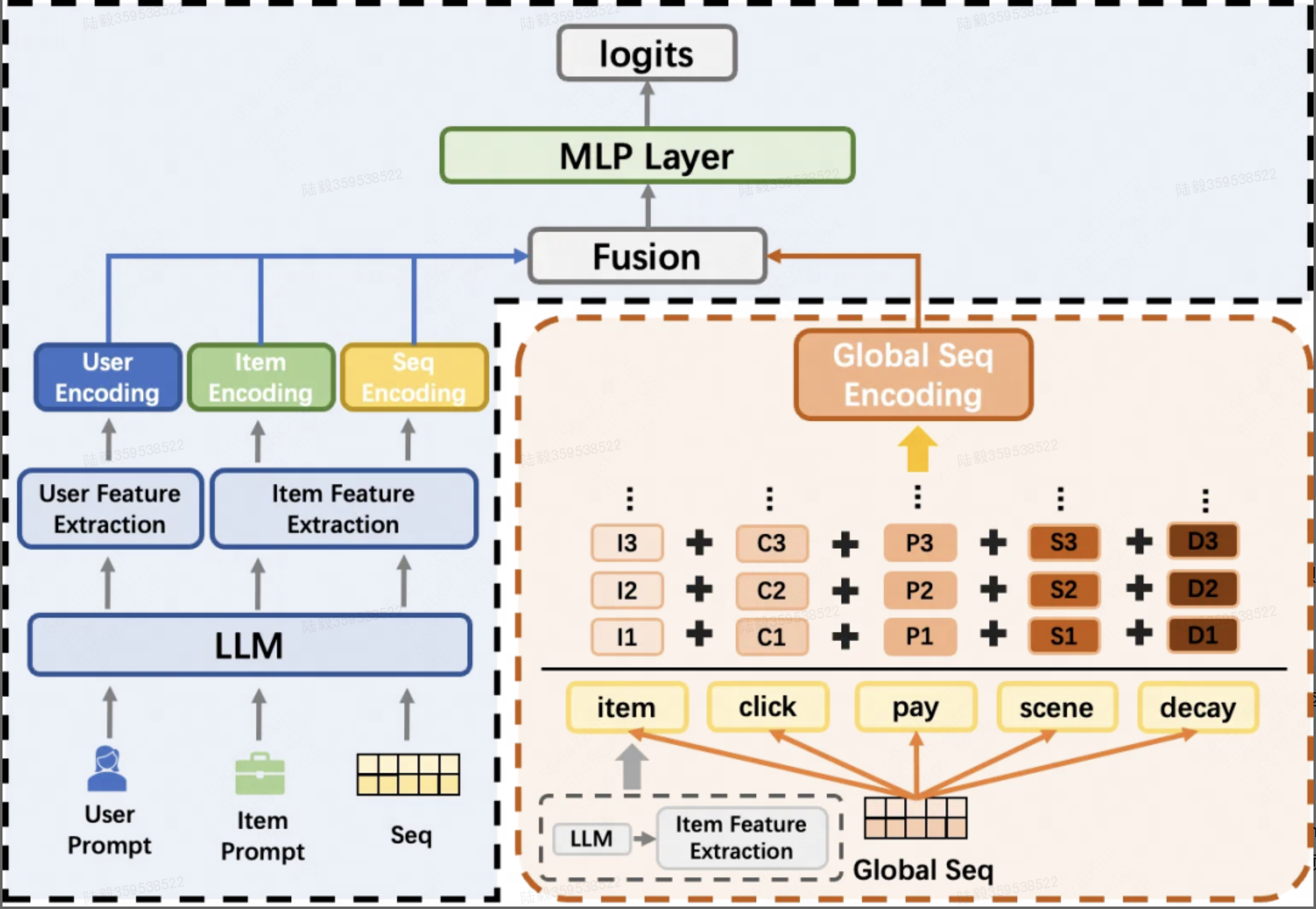
LLM编码模块
商品特征:使用结构化的商品描述作为prompt输入,通过LLM编码生成商品特征向量,由此可以确保商品特征的丰富性和语义表达能力
画像特征:使用结构化的人群描述作为提示输入,通过大型语言模型编码生成用户向量,捕捉用户的静态属性和偏好
序列特征:对每一条重要的历史序列,使用其中包含的商品的LLM编码向量堆叠后的矩阵表示进行序列表征。由于现有序列存在大量重叠,算法团队引入了全局行为序列(global seq),添加了点击label、成交label、时延、场景等信号,这些信号用类似于bert的位置嵌入(pos embedding)方式加入。
任务预测层(CTR模块)
经过LLM编码模块之后,算法团队将LLM编码模块得到的用户/商品向量根据所属特征部分按照传统推荐模型的结构进行组织,通过特征融合层和MLP层,预测最终的CTR分数。
3.2 LLM和ID模型的对齐
LLM应用到推荐模型,一个很大的问题是对齐问题。推荐系统都是以ID为主的模型,包括user id、item id等,模型基于用户行为等协同过滤信号学习这些id embedding。因此,如何对齐两种模态非常重要。
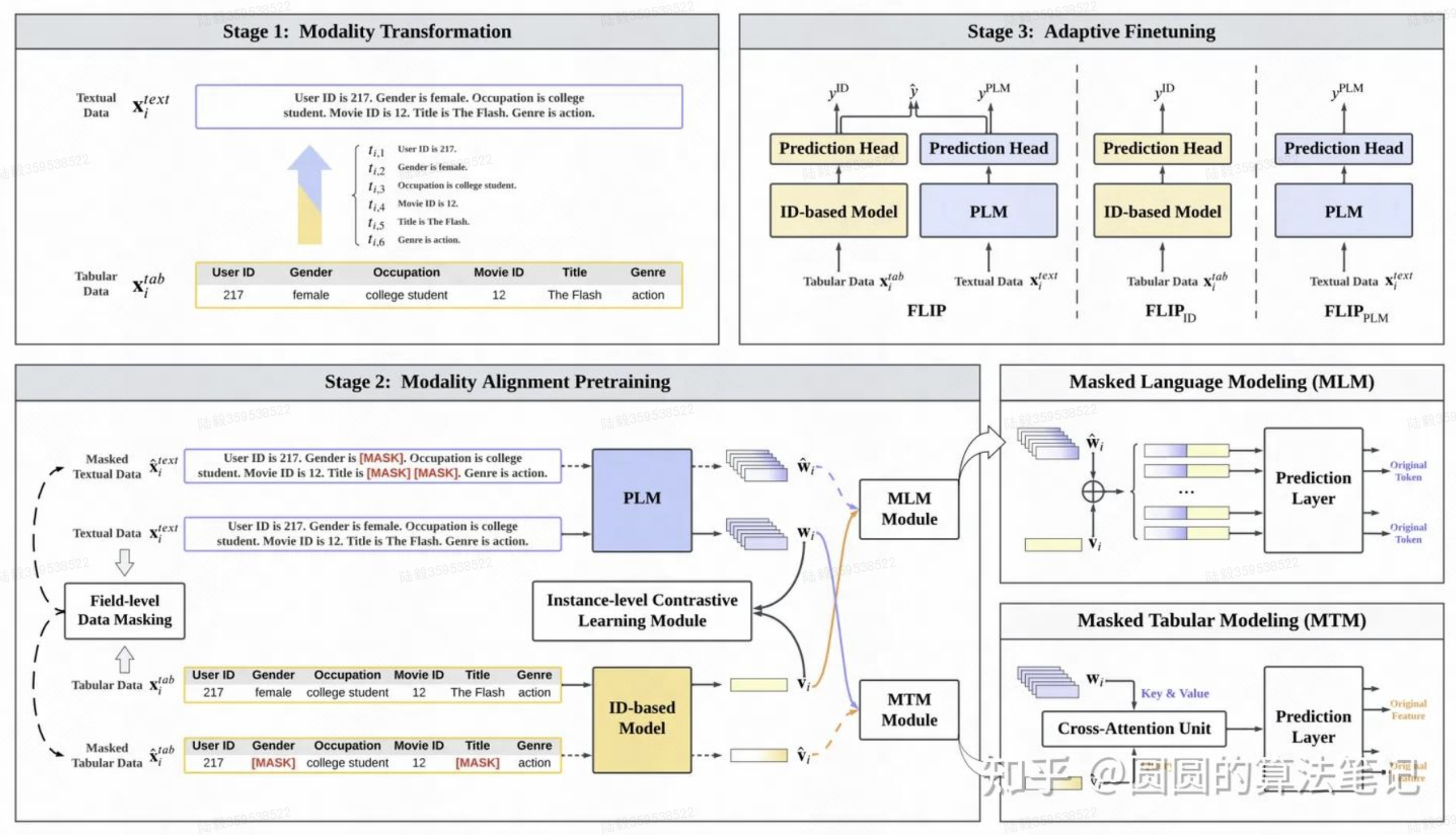
FLIP: Towards Fine-grained Alignment between ID-based Models and Pretrained Language Models for CTR Prediction(华为)
核心解决方法是通过预训练对齐ID模型和语言模型的表征。文中引入了类似MLM的方法和对比学习的方法。在MLM中,对特征的文本表示和ID表示分别进行mask,使用上下文两种模态的信息进行被mask部分的还原。在对比学习中,对于同一个样本特征的ID和文本表示方法作为正样本对,使用对比学习拉近其距离。在预训练后,使用ID模型和LLM的预测结果做加权求和得到最终预测结果,使用下游数据进行finetune。
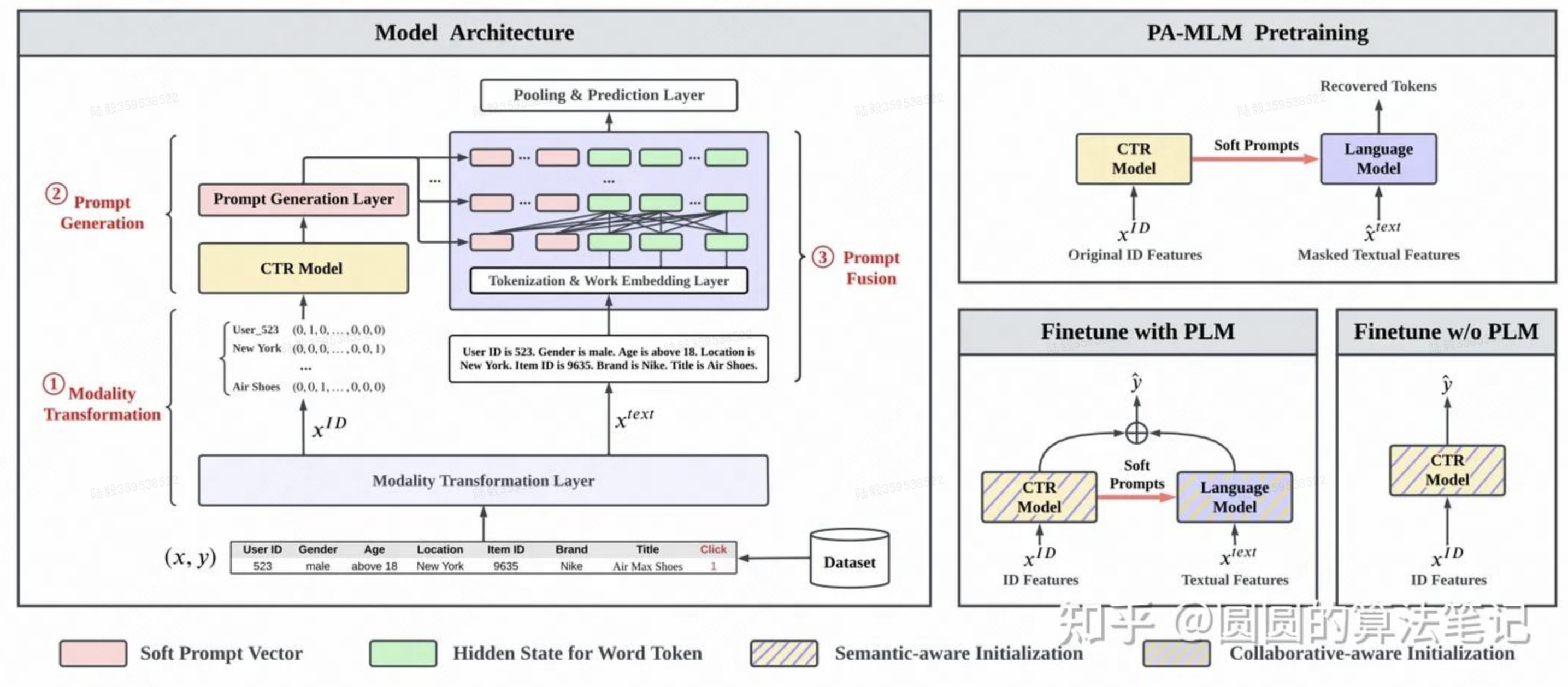
ClickPrompt: CTR Models are Strong Prompt Generators for Adapting Language Models to CTR Prediction(华为)
提出了一种用ID模型和LLM对齐的方法,利用ID模型生成prompt,作为prefix拼接在transformer每一层,通过预训练任务实现ID模型和LLM模型的对齐。首先,将CTR预估中每个样本的特征转换成文本描述的形式。接下来,将原来的CTR模型中间层的embedding作为prompt,拼接到上述文本描述的前面。将拼接了prompt的文本描述输入到LLM中,让LLM生成token序列,再基于token序列对预测结果进行还原。通过这种用CTR预估模型embedding作为prompt的方式,实现ID的CTR模型和LLM的CTR模型对齐的目标。在下游应用部分,使用两个模型的预测结果相融合,作为最终的预测结果,拟合相应的Label。
3.3 LLM解决长尾推荐
推荐系统基于纯ID embedding训练模型,对于那些长尾的user、item,数据量少,id embedding就学习不充分。这种场景下,LLM就展现了其特有的优势,借助大模型的文本建模能力,将id表征解耦成泛化性更强的组件,提升长尾推荐效果。
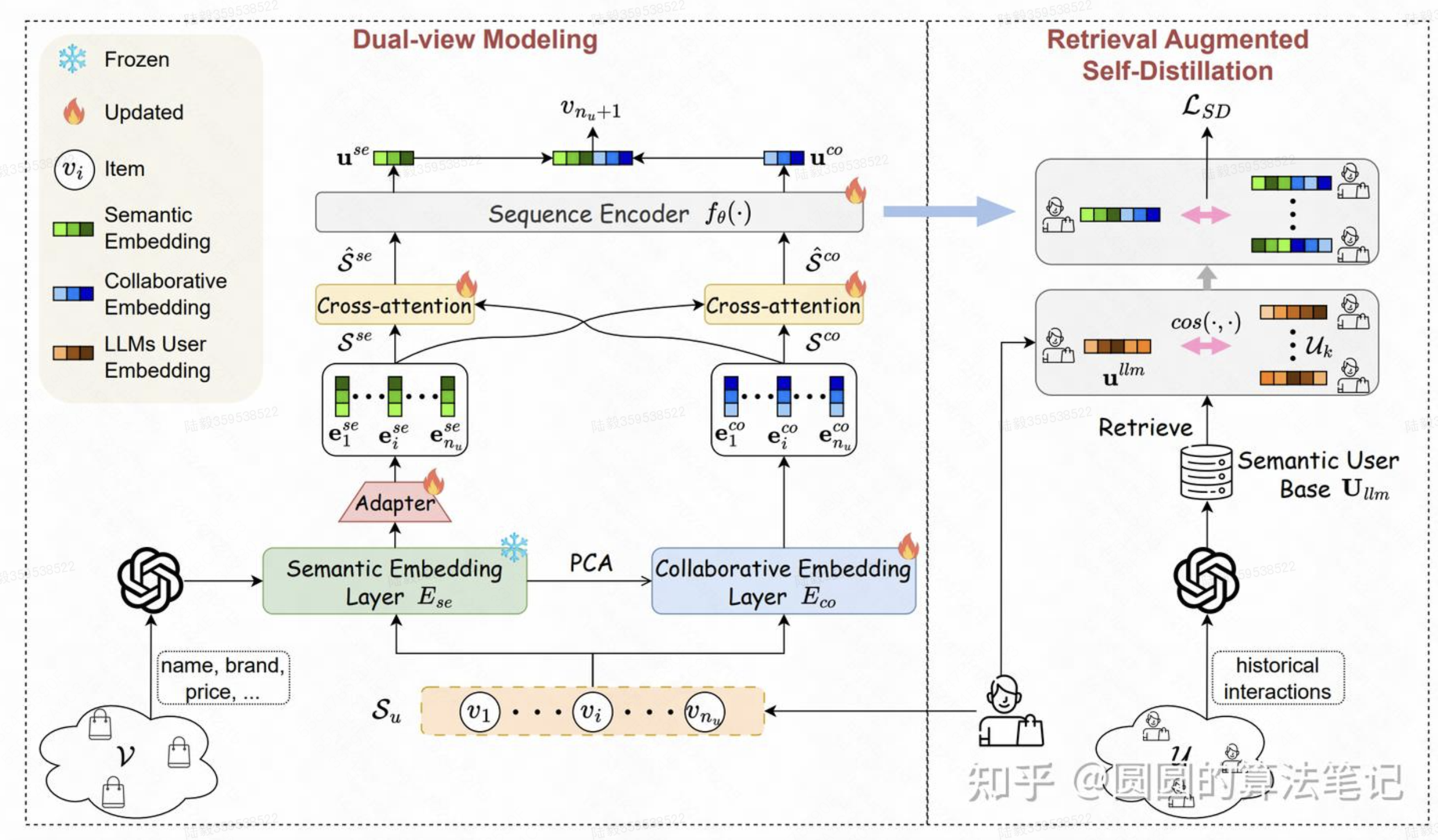
LLM-ESR: Large Language Models Enhancement for Long-tailed Sequential Recommendation(华为)
在推荐场景中,有相当一部分用户只交互过少数(10个以内)的item,这种行为稀疏的用户推荐模型的打分效果会显著下降。为了解决这类长尾user的推荐问题,本文采用了LLM的文本能力提升长尾user表征的学习。核心包括dual-view modeling和retrieval-augmented self-distillation两个部分。
dual-view modeling:对于一个user,使用文本侧和协同过滤侧两个encoder生成user表征。文本侧使用大模型基于item的文本描述生成item表征存储起来,然后使用一个类似Transformer的Encoder对用户历史行为的item文本embedding进行建模;协同过滤测就是最基础的基于id序列的Transformer序列建模。两部分信息一方面使用cross-attention进行融合,另一方面输出结果页直接拼接到一起融合。
retrieval-augmented self-distillation:基于user的表征检索出表征最相似的topK个其他用户,让当前用户的表征和这些检索出来的用户表征的L2距离尽可能小,作为指导目标,蒸馏其他user表征的知识,让长尾user的表征学习的更充分。
3.4 LLM让推荐模型具备可解释性
推荐模型是黑盒,对于打分缺乏可解释性。而LLM是文本模型,可以通过文本生成传达信息。因此,文中通过LLM和推荐模型对齐,实现LLM的可解释性。
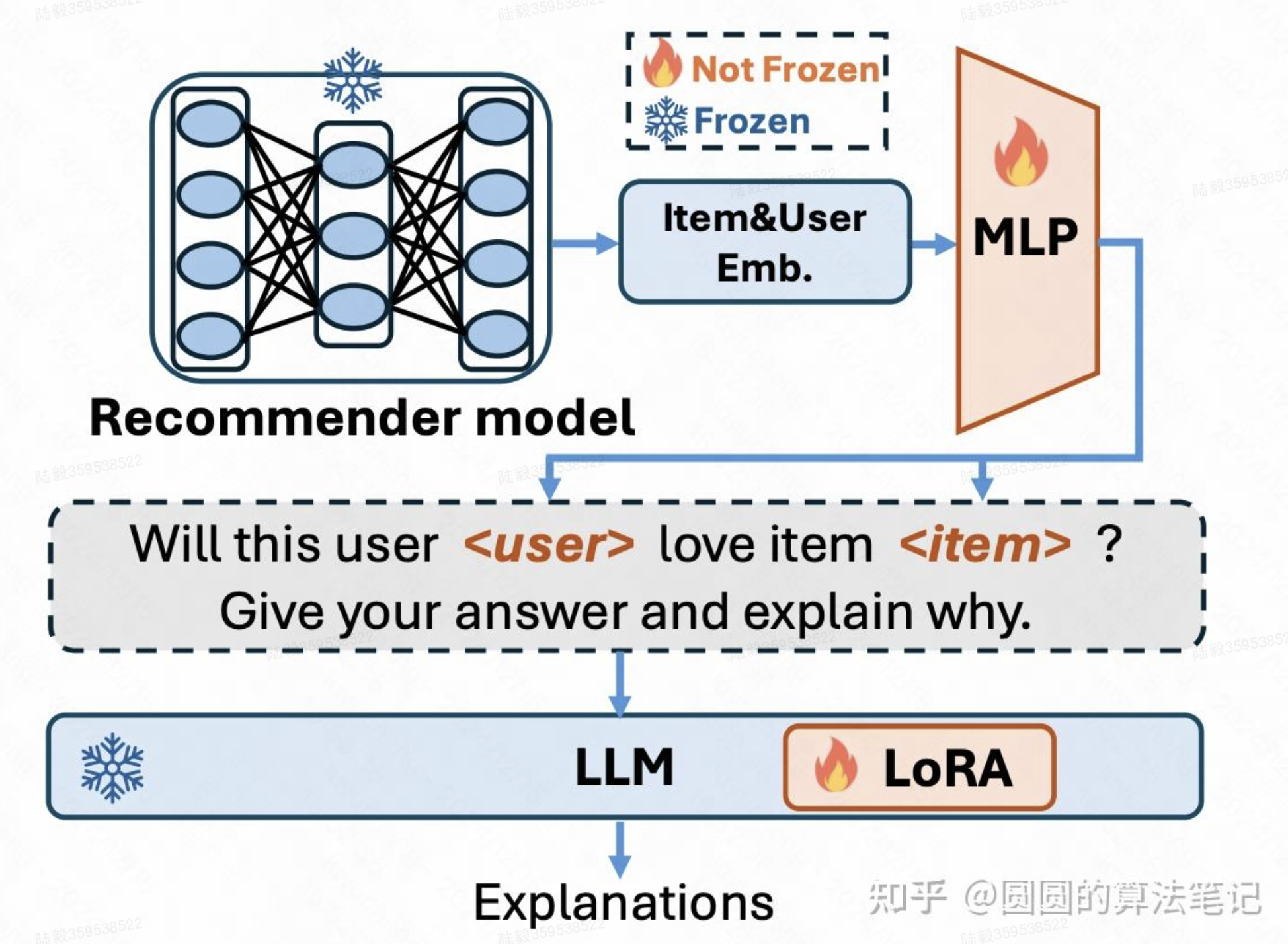
RecExplainer: Aligning Large Language Models for Explaining Recommendation Models(微软)
使用LLM实现推荐系统的可解释性。文中的一个核心假设是,如果能让LLM产生和一个训练好的推荐模型具备相似的预测结果,LLM就能模拟推荐模型的计算逻辑,进而就可以让其生成文本解释其预测逻辑,实现推荐模型的可解释性。文中设计了6种任务对齐推荐模型和LLM,包括下一个item预测(注意这里是以推荐系统模型的预测结果为目标,而非下一个item的ground truth)、item排序、用户兴趣的二分类预测、生成item的描述、使用GPT数据继续训练防止灾难遗忘等。同时,借助多模态领域的建模思路,在这些任务中奖id随机替换成推荐系统中的embedding,当成另一个模态的信息,实现LLM对推荐系统embedding模态的理解。
3.5 LLM提供外部知识
LLM中蕴含着大量的世界知识,直接将这些知识提取出来加入到推荐模型中,通过从LLM中提取知识信息,增强推荐系统模型的训练。
Enhancing Sequential Recommenders with Augmented Knowledge from Aligned Large Language Models(蚂蚁)
对于一个item,将其相关信息输入构建prompt输入到LLM中,让LLM生成一些数据集中没有的知识信息,并通过一个文本Encoder编码成item embedding。文本embedding和原始的id embedding融合到一起输入到推荐系统模型中。由于LLM生成的文本信息可能包含很多和推荐无关的部分,并且由于是提前生成的,无法更新LLM参数。因此文中直接建模一个从LLM中采样生成文本知识信息的分布,基于这个分布从LLM生成的文本中采样对推荐有效的信息。
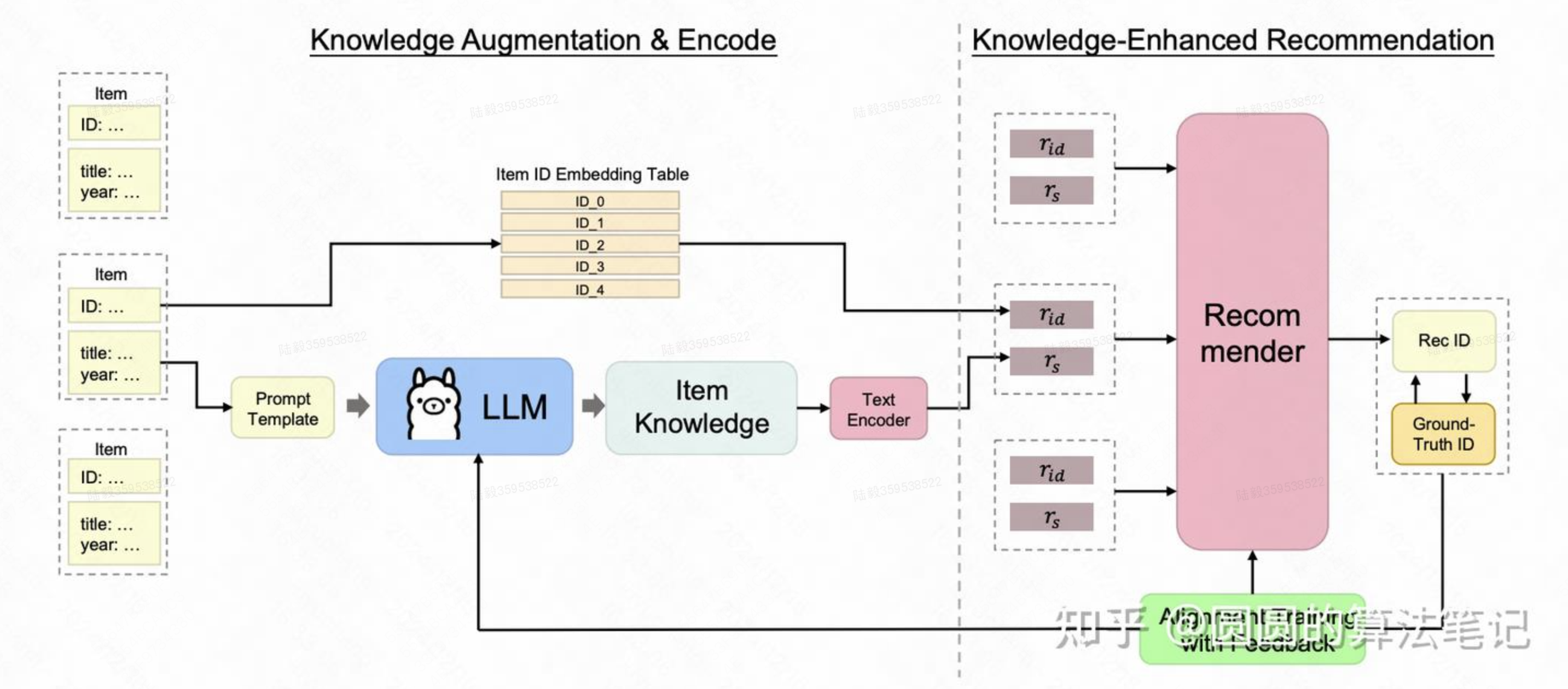
3.6 端到端生成式推荐模型
OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment(快手)
第一个在现实场景中超过当前推荐系统的端到端生成式推荐模型,在快手的主要场景部署,观看时长+1.6%。
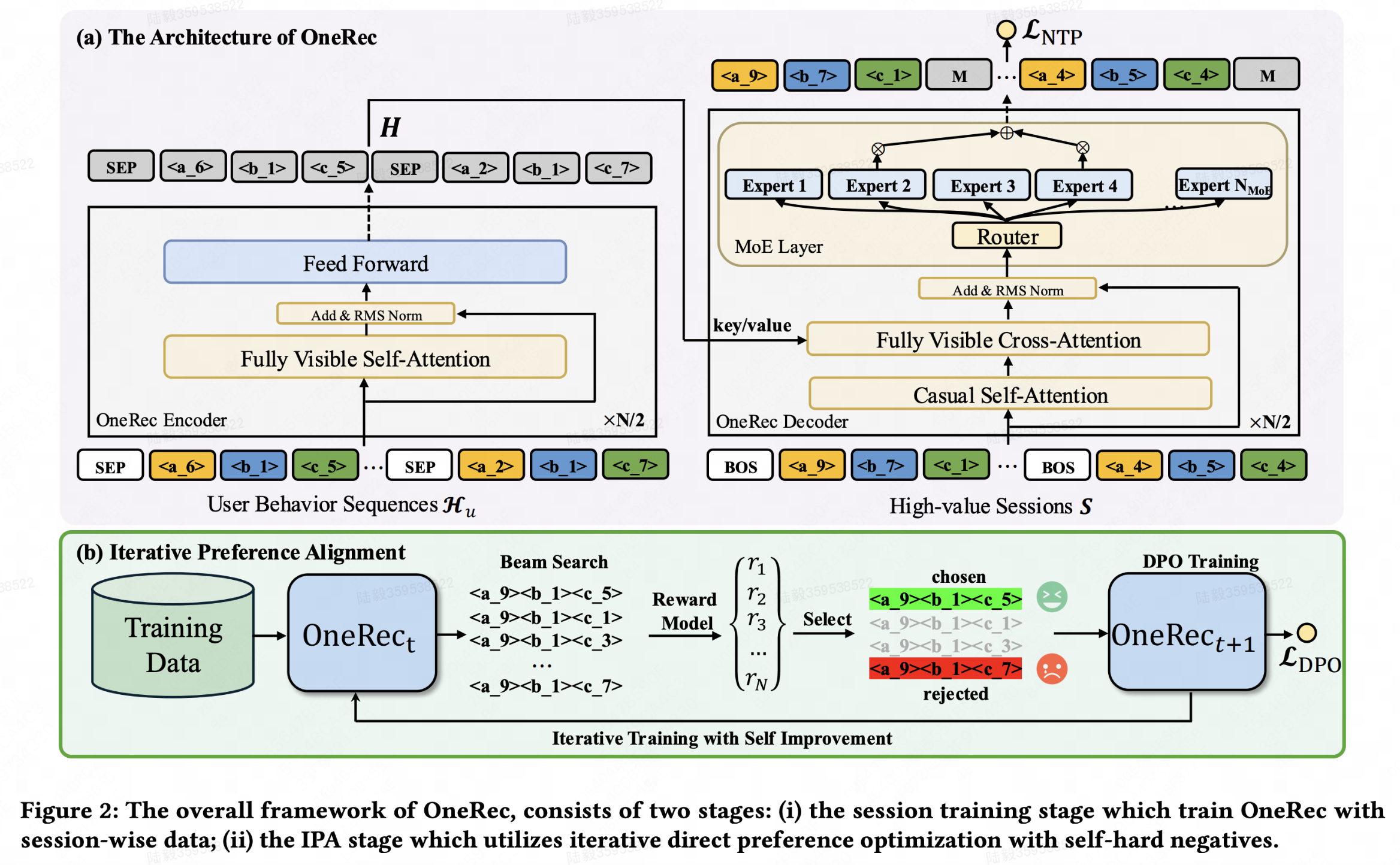
特征层面:OneRec将正向历史行为序列作为输入,例如用户有效观看或交互(喜欢、关注、分享)过的视频,OneRec的输出是一个视频list。对于每个视频使用与user-item实际行为分布对齐的多模态嵌入来描述它们
session-wise推荐结果生成:与传统的仅预测下一个视频的point-wise推荐方法不同,会话式生成旨在根据用户的历史交互序列生成一系列高价值会话,这使推荐模型能够捕获推荐列表中视频之间的依赖性。具体来说,session是指响应用户请求而返回的一批短视频,通常由5到10个视频组成。会话中的视频通常会考虑用户兴趣、连贯性和多样性等因素。制定了几项标准来确定高质量的会话,包括:
用户在一个会话中实际观看的短视频数量大于或等于5个;
用户观看会话的总时长超过一定阈值;
用户表现出互动行为,如点赞、收藏或分享视频;
利用奖励模型的可迭代偏好学习:引入了一个预训练的会话式奖励模型来判别当前推荐模型的响应优质程度,构建偏好样本数据集,以此不断的迭代地训练推荐模型。
Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation(微信)
直接使用大模型进行item的全库生成推荐,不再需要item候选集,核心包括基于LLM的item ID生成以及LLM的推荐系统finetune两个部分。
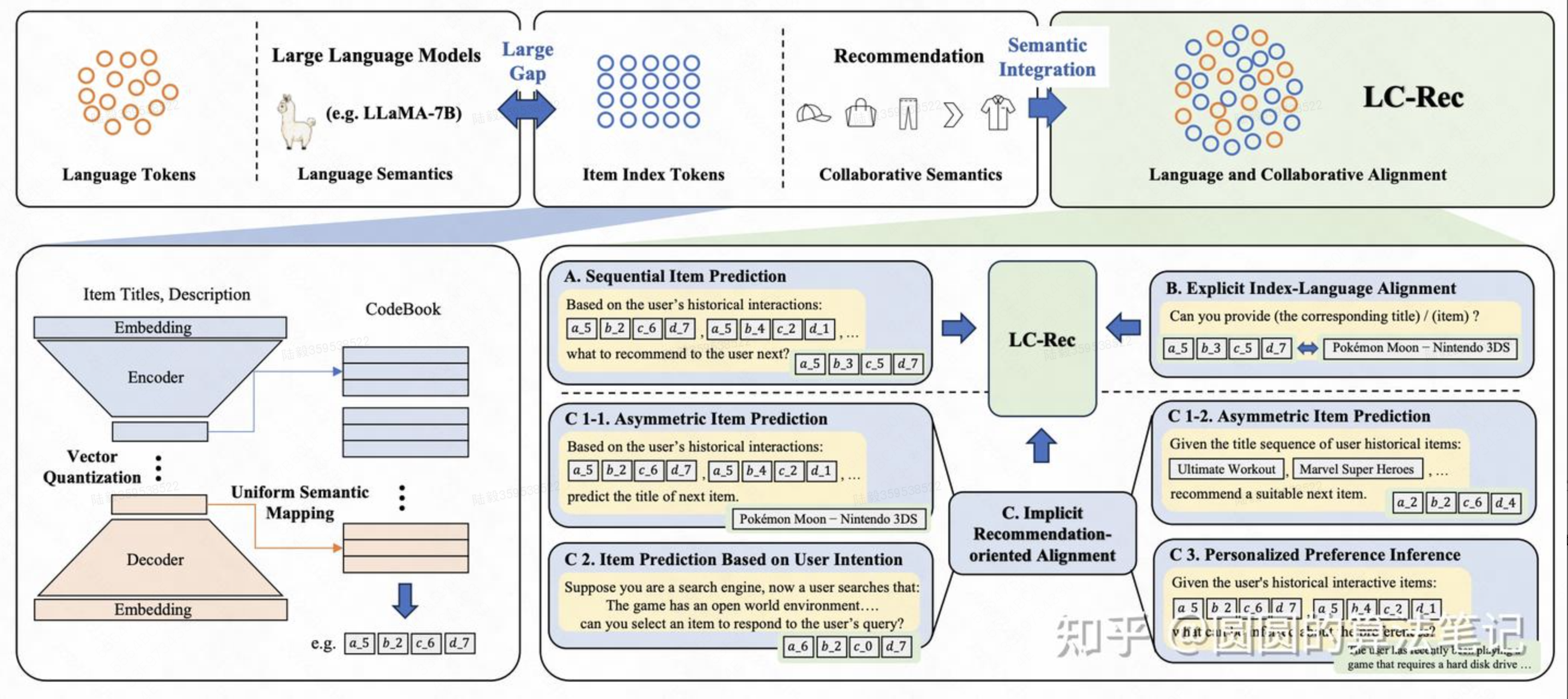
文中基于item的文本标题、描述等文本信息,使用LLM生成每个item的表征,再基于Vector Quantization等量化技术,将每个item的表征进行各个维度的离散化,得到每个item的ID作为索引。另一方面,引入了多种类型的任务对LLM进行finetune,让LLM能够适配这些item ID,并融合推荐领域的知识。在finetune阶段,引入了包括next item预测、根据item的标题或描述预测item的索引ID、根据item ID序列预测用户的兴趣偏好(数据从GPT3根据历史item文本序列生成用户的兴趣偏好描述)、根据用户搜索文本预测item ID等近10种任务进行LLM的finetune,充分对齐新引入的item ID、推荐任务和文本含义。经过finetune后,这些item ID直接作为单次加入到LLM的vocabulary中,基于LLM进行下一个item推荐。